
Readme
Introduction
This project is a video behavior recognition project based on deep learning. It mainly contains three modules, including a player module, an output log module, and a model training module. Reading this document you can know the following:
- How to divide the data set into training set and test set proportionally? (Take UCF101 as an example)
- How to convert a video data set to a picture data set?
- How to call Pytorch’s own pre-training model training pictures?
- How to modify the pre-training model?(Take Inception-v3 as an example)
- How to make a player software with the function of recognizing human behavior video?
简介
本项目是基于深度学习的视频行为识别项目,主要含有三个模块,包括播放器模块、输出日志模块、模型训练模块。查阅本文档你可以得知以下内容:
- 如何按比例分割数据集为训练集与测试集?(以UCF101为例)
- 如何将视频数据集转为图片?
- 如何调用Pytorch自带的预训练模型训练图片?
- 如何修改预训练模型(以Inception-v3为例)?
- 如何制作一个具有识别人体行为视频功能的播放器软件?
参考项目
感谢大佬!
本项目Github
Preview 效果预览
这个项目做的比较早了,当时没有系统学过Qt前端,所以界面丑一点哈哈,看一下效果就行了
Homepage 播放器主界面
The left side is the video preview, you can drag the progress bar to watch, you can also pause the playback, and the right box can output the identification log.
左侧为视频预览,可以拖动进度条观看,可以暂停播放,右侧方框可以输出识别日志。
上传视频 & 识别结果
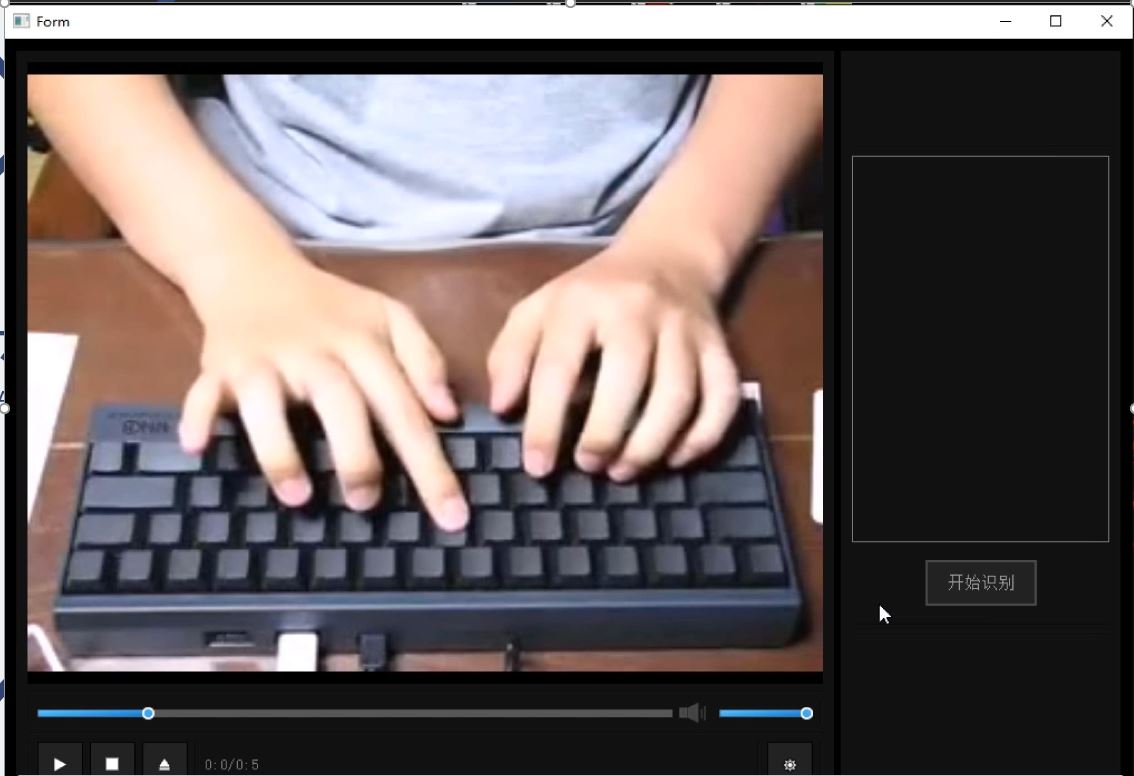
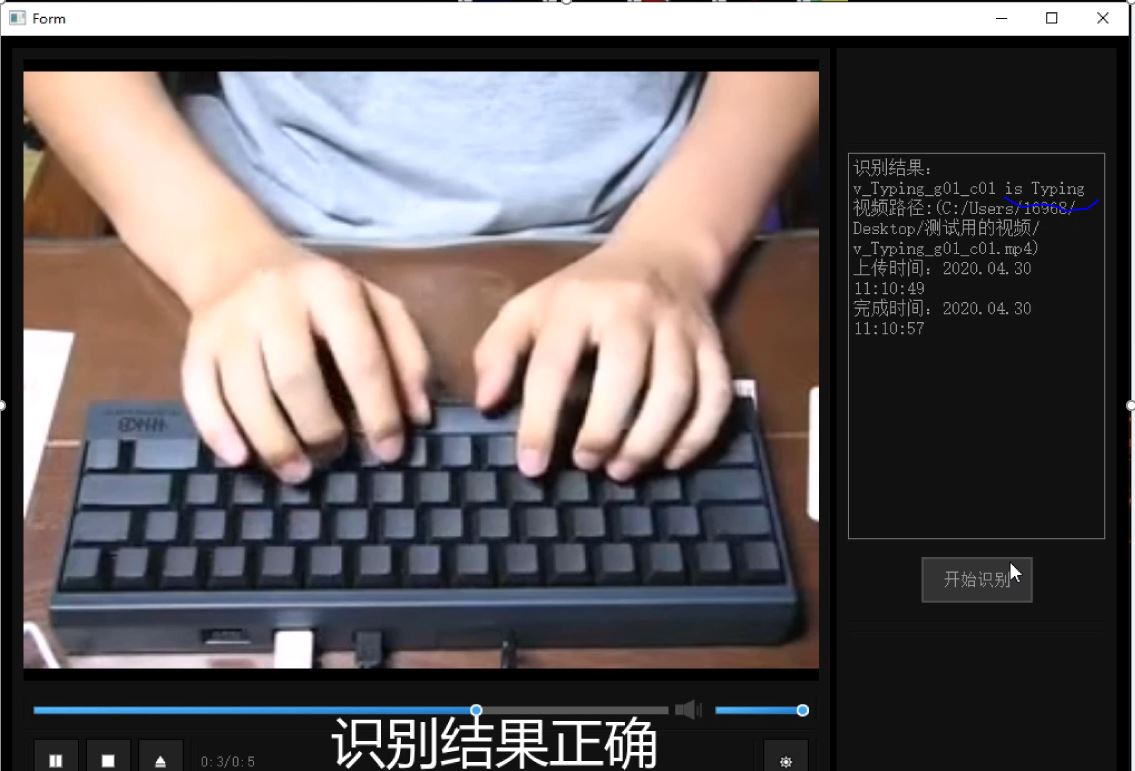
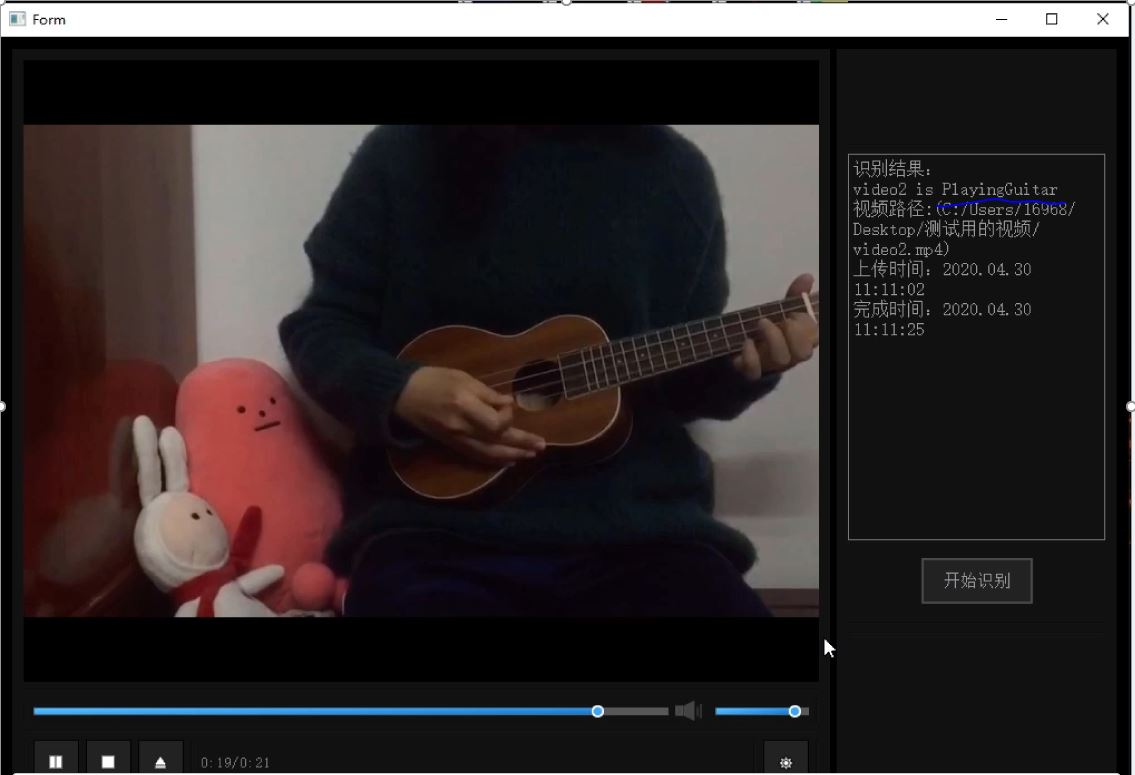
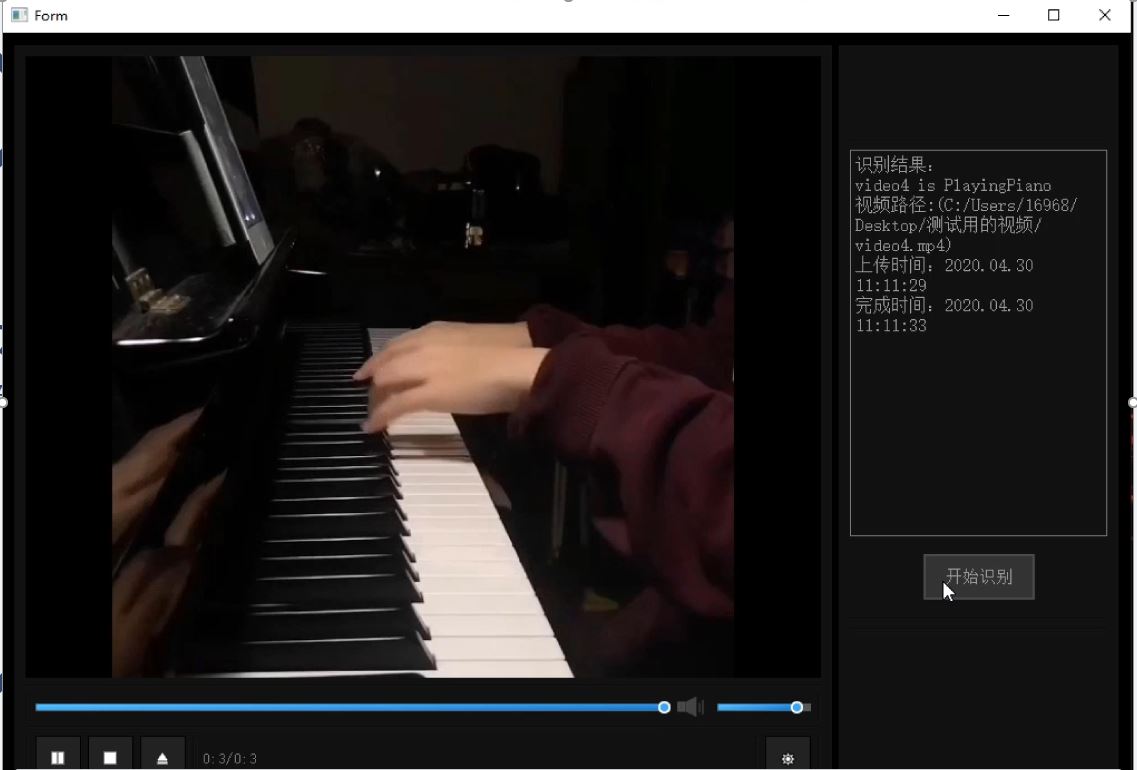
These video actions are all human actions in the UCF101 data set. The first video comes from UCF101 training set, and the latter two are recorded by ourselves and are not included in the data set. The above three video recognition results are all correct.
这些视频动作均为UCF101数据集中的人体动作类,其中第一个视频为训练集中的视频,后两个为我们自己录制,不包含在数据集中,用于测试的视频。以上三个视频识别结果均正确。
Code interpretation 代码解读
Split the video data set 分割视频数据集
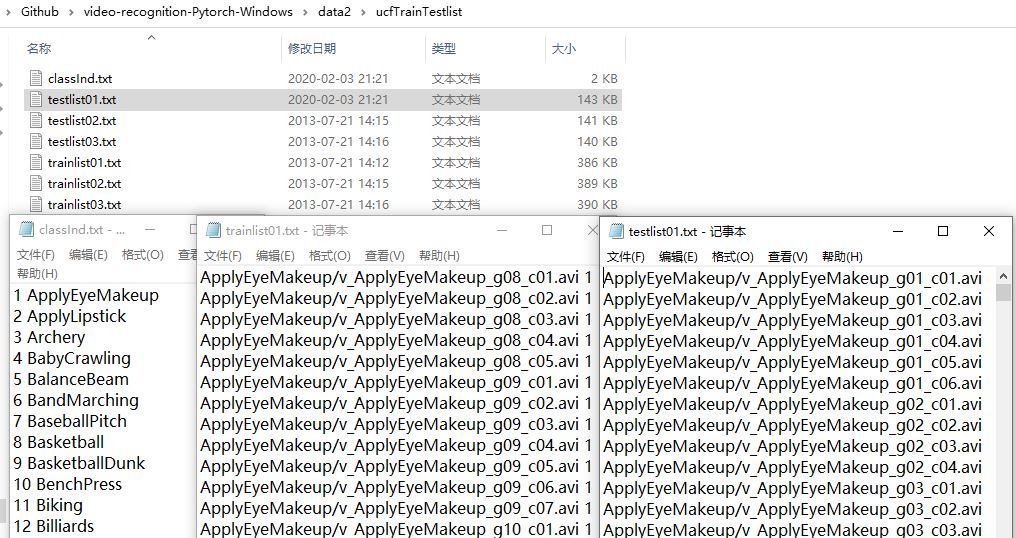
UCF101 officially provides a txt file for dividing the video data set into train set and test set. We only need to read the file list and process it on the string to obtain the file names in the training set and test set, and then use Functions in python to create folders and move videos.
UCF101官方提供了txt文件用于分割视频数据集为训练集和测试集,我们只需要读取文件列表,并对其进行字符串上的处理,从而获得训练集和测试集中的文件名称,再使用python中函数创建文件夹、移动视频即可。
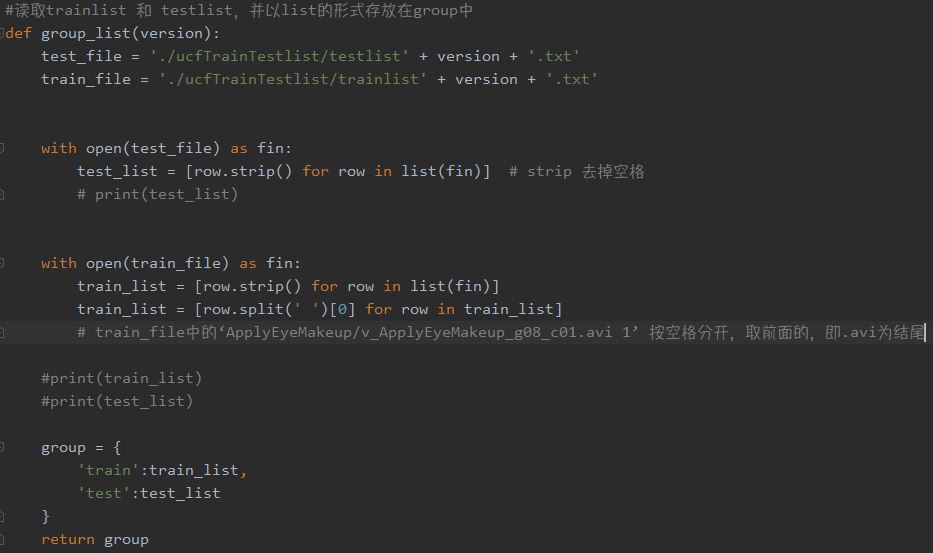
group_list函数中,首先获取参数version,该参数代表读取的是ucfTrainTestlist中的哪一个组合,总共有01、02、03三种组合。
利用strip、split等字符串操作,读取每一个视频路径,获得的train_list、test_list为列表,列表中每一项格式如下,以此类推。
1 | ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c01.avi |
group是包含了train_list和test_list的字典。
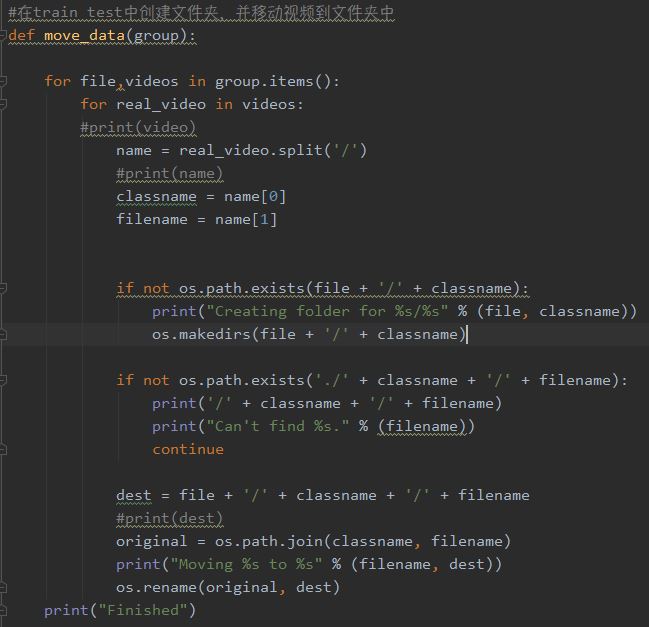
move_data的参数为上面获得的group,在函数中,首先对group中字符串进行分析,获得动作名和视频文件名,并利用python中函数创建文件夹,移动视频。以ApplyEyeMakeup/v_ApplyEyeMakeup_g08_c01.avi为例子。
1 | #这是group中trainlist列表中的第一项 |
1 | ''' |
以上操作后可以获得两个文件夹,train和test,目录结构如下:

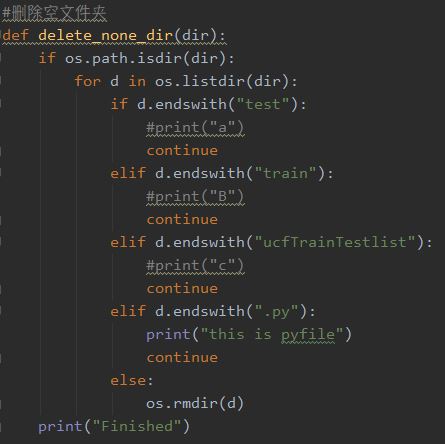
使用函数将空余文件夹删除
就此,我们成功将训练集与测试集分开,接下来要对视频进行解帧,从而获得图片。
Use ffmpeg deframe videos into pictures
视频解帧为图片
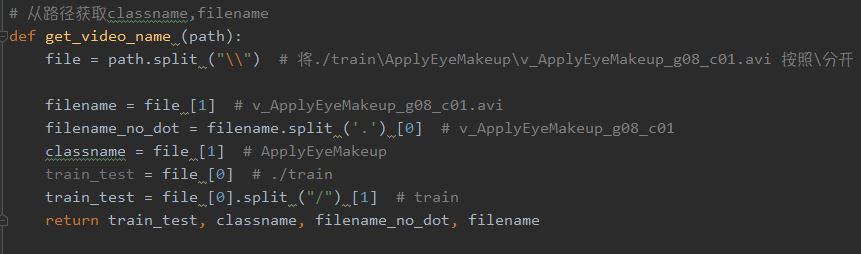
见图片代码注释可知,get_video_name函数可以返回四个值,分别是
1 | train_test:视频来源于训练集or测试集 |
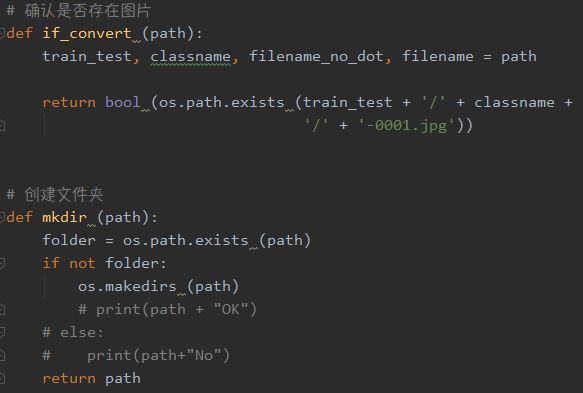
接下来的conver函数将调用以上两个函数用于确认是否存在图片,以及创建文件夹。
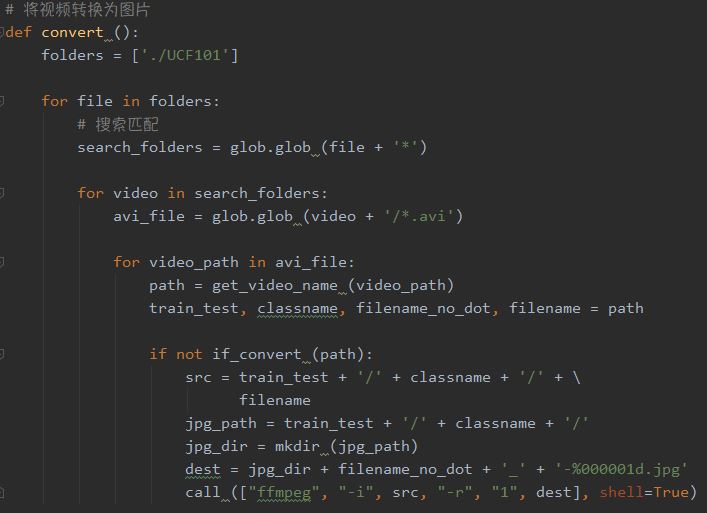
1 | ''' file:train/test |
获得的文件结构如下:

至此,我们已经完成了数据预处理的基本操作,接下来开始是训练模型部分。因为接下来的训练只会使用到图片,所以要将train和test中的视频手动删除。