
接上文
Model Training 模型训练
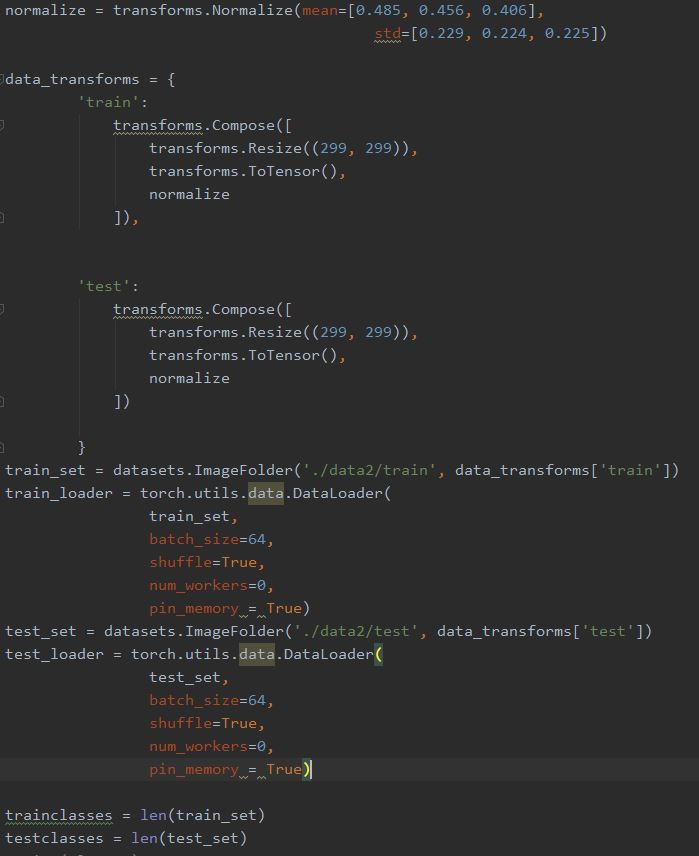
使用Pytorch中的DataLoader导入,前面之所以设置那样的文件目录是因为这是DataLoader的要求,详见Pytorch官方文档。
Resize(299,299)是模型Inception-v3的需要。
batch_size = 64是我们根据实验获得的最佳超参数,可以根据实际个人配置进行调整。
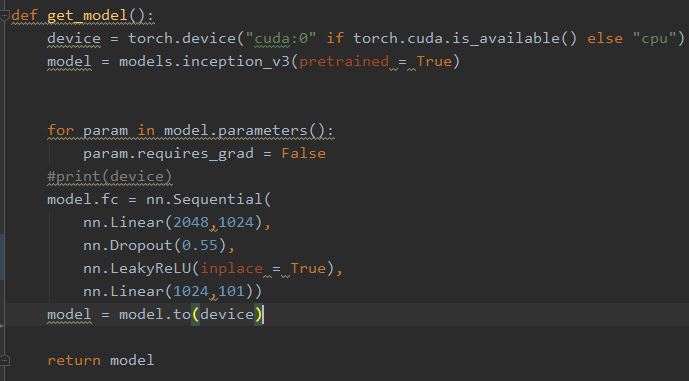
在get_model函数中调用inception-v3,并添加两个线性全连接层,添加Dropout和LeakyRelu防止过拟合。
这里仅仅做了最简单的修改,Pytorch预训练模型自由度很高,支持屏蔽某些层等更高级的修改。
最后一个Linear的最后一个参数应该为动作类别的数量,可以通过读取文件夹个数获取,这里直接写101是因为UCF101总共101个动作,偷了个懒XD
之后的训练过程和图像识别基本一致,这里简单解释,详情可以参照Pytorch官方案例。
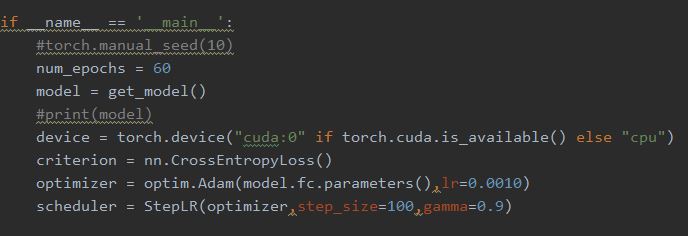
定义模型,device,optimizer等,optimizer类型和learning_rate均可以修改。
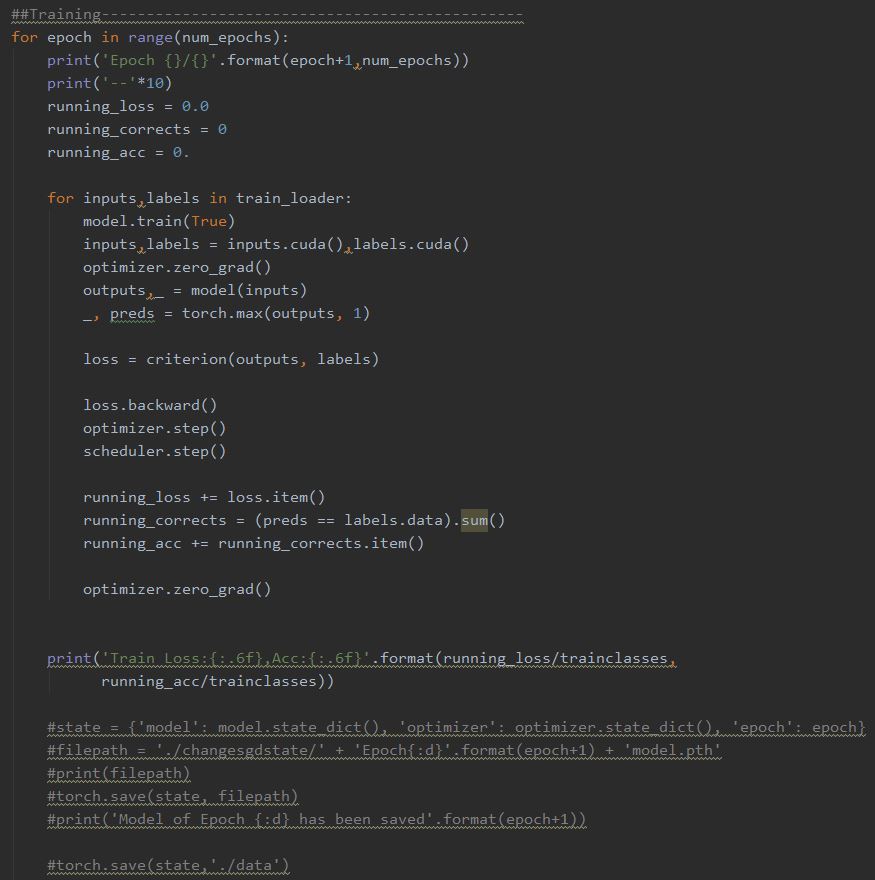
训练阶段,注释部分可以保存模型state,中途停止后可以读取State继续运行。
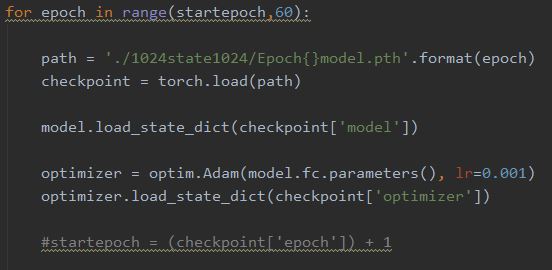
上面这张图片读取了state,这样我们一旦停止训练,下一次无需从Epoch=1开始,state中已经保存了相关参数。
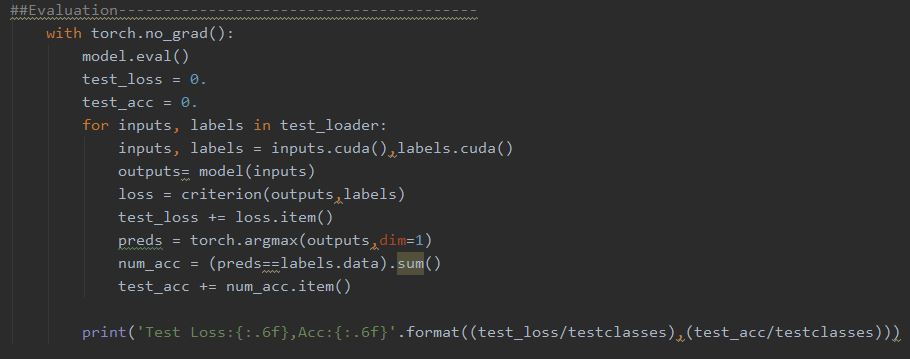
验证部分。
实际上真正过程中应该分为Training,Testing,和Validation,但是由于UCF101官方给的文件仅区分了training和testing,且作者做这个项目的时候对于深度学习不甚了解,所以本项目中没有区分testing和validation。
至此,训练和验证部分结束,每一个Epoch我们均保存了参数,挑选最佳参数读取即可。接下来将进入软件开发部分。
前端部分参照各大Qt教程即可,这里简单写一下如何使用我们训练获得的参数,如何用来识别自己录制的视频。
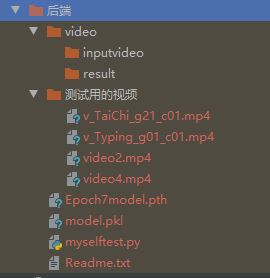
首先,我们需要保存get_model()中的模型,并命名为model.pkl。
并按照一下文件目录放置文件。Epoch7model.pth为我们保存的一个state,要识别视频,请将测试用的视频文件夹中【一个】视频复制到inputvideo文件夹中。
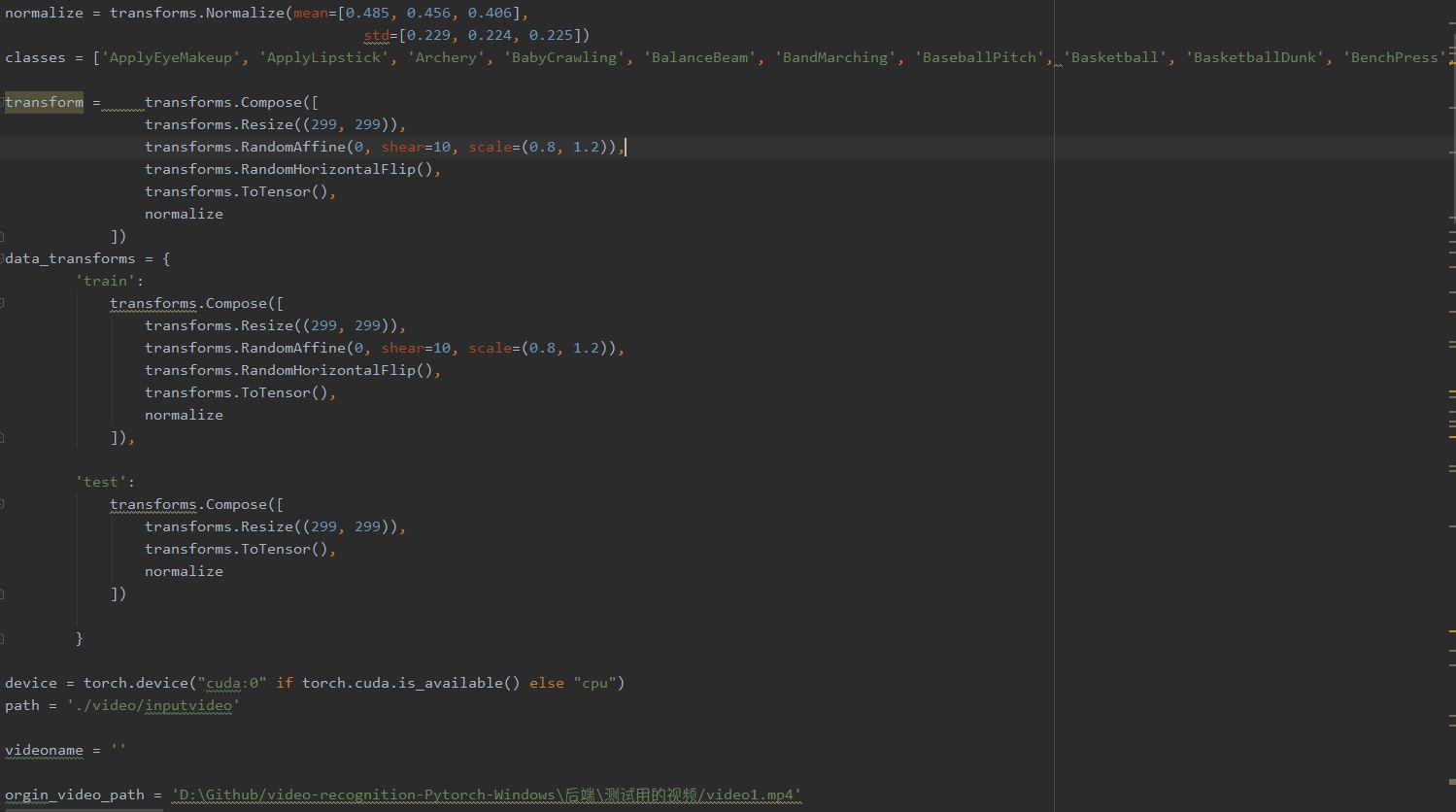
基本操作,定义transform,device,path
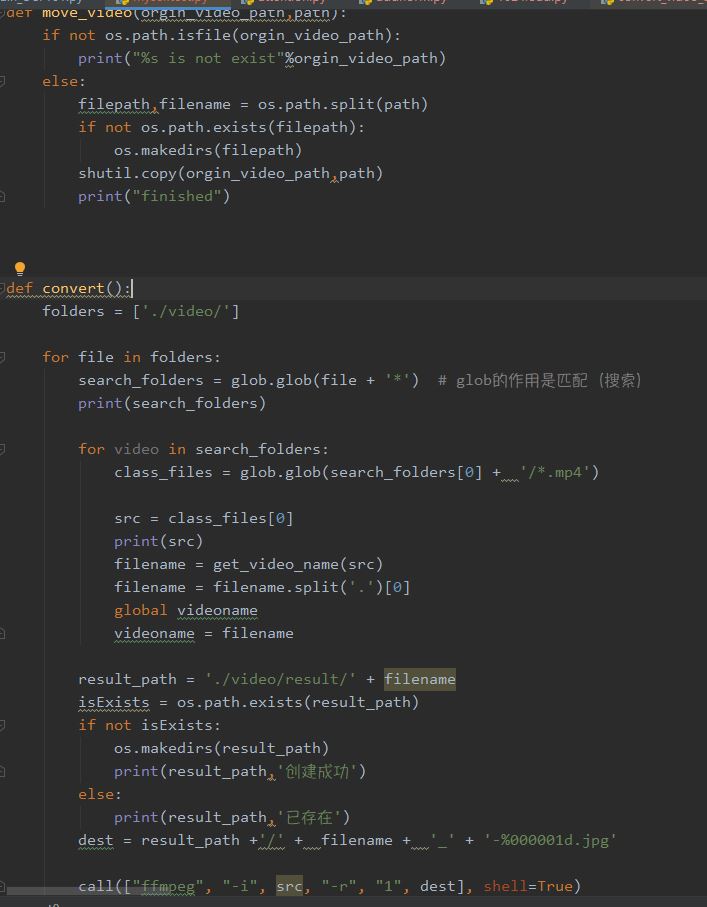
move_video和convert和前面基本一致,都是为了移动视频并转换为图片。

获取视频名称
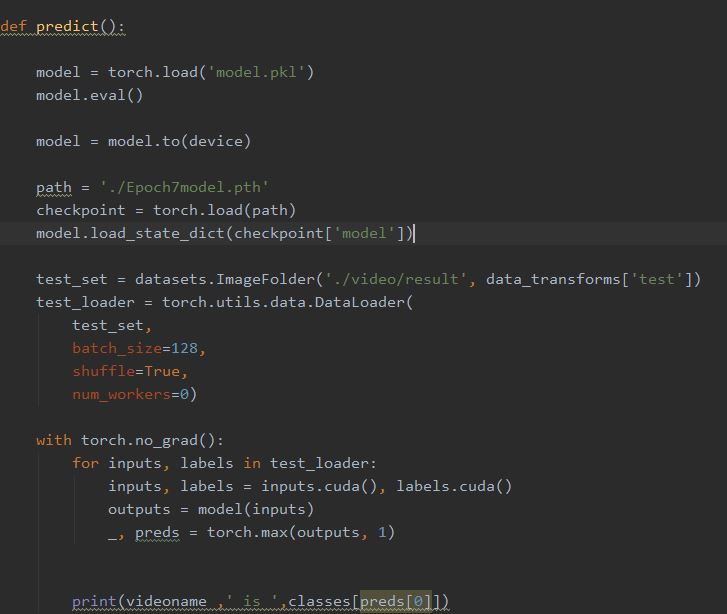
读取参数导入model。
preds为列表,第一项为可能性最高的动作编号,如ApplyEyeMakeup的编号为0,若该动作最有可能是ApplyEyeMakeup,则preds[0]=0,从classes中获取classes[0] = ApplyEyeMakeup
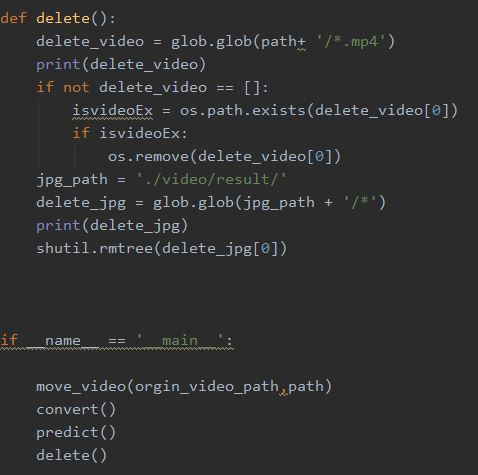
为了下一次识别的需要,在识别后需要将inputvideo和result中的视频图片删除。
本项目代码解读就此结束,获得的识别准确率、训练测试准确率、loss等数据由于论文尚未发表,暂时不公布。之后会来除个草。